When you accept GPU rentals from anyone willing to provide a suitable card - as we do - you have to be very careful. Sometimes, it can feel like shopping for a used car: if you don't have a reliable way to verify your purchase, you risk overpaying or getting scammed.
Well, not anymore. We couldn't accept this level of uncertainty, so we employed a 100% deterministic LLM to outsmart GPU scammers once and for all. Read on to discover how an ingenious idea and a sprinkle of Python magic helped us find a bulletproof method and reduce the GPUs needed for reliable verification by 240x.
Scam-Proofing the GPU Market
Why test GPUs at all? At Reef Technologies, we’re creating a platform to sell GPU computing time from anyone online. Delivering high-quality service is crucial. So, we had to eliminate any uncertainty in GPU verification.
One way to test whether appropriate hardware is provided is to run something on it and verify the result. LLMs are popular, so let’s run an open-source one. Since they require a lot of VRAM, choosing a model with the right number of parameters allows us to ensure that at least X GB of VRAM is available. But how do we do that?
We started by taking a sample input. Then, we calculated the answer ourselves. Next, we compared the results and timing with the GPUs we needed to verify.
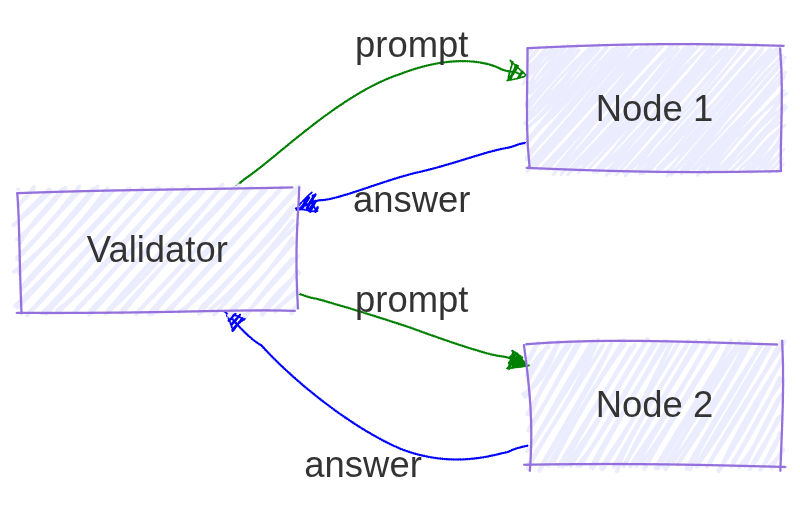
Imagine you’re a malicious provider with 100 nodes (each providing some GPU power), one node is really powerful, while the others are garbage. You receive the same test request on all 100 nodes. Cheating is simple: you calculate a result on the strongest node. Then, share the answer with your other nodes, and they will act as if they did the calculation themselves.
<img src="/assets/blog/malicious-GPU-provider-detection/cheating.jpg"alt="Cheating scenario">One may say, "Send different tasks to each node!"
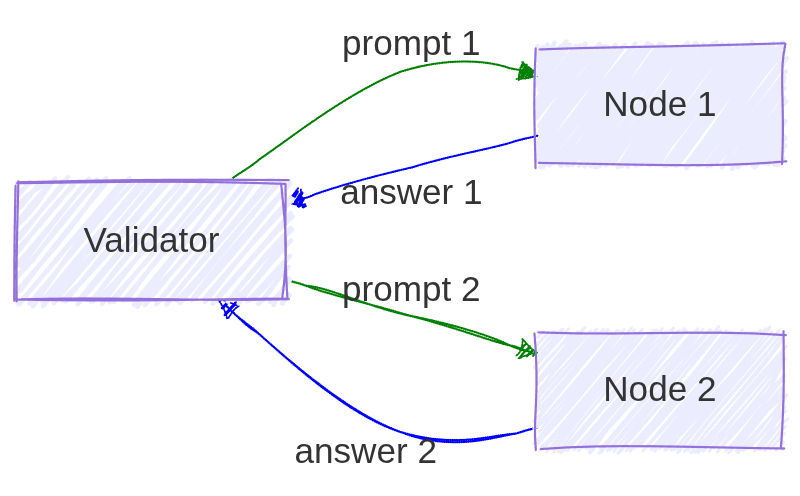
But now our poor validator has to know answers to all the questions, i.e., perform as many calculations as there are nodes in the system. That’s a lot of work!
Also, aside from the problems above, let’s remember that we’re in the LLM era and we want to run LLMs on the GPUs, thus the validation task will likely not be just “2+2=?” but rather some text input completion using a huge LLM - so that we probe nodes on real-life tasks. And LLMs naturally introduce randomness - same input may produce different output - making direct comparison of validators’ and nodes’ answers unreliable.
So we’re in a bit of trouble here.

Deterministic LLMs & Prompt Batching to the Rescue
To solve the problem and make sure hardware differences could no longer be hidden, we decided to enforce strict determinism in our LLM testing. (Shame you can't do this when shopping for a car...)
So, how did we do it in practice?
Step 1: Seeding Everything
Usually, libraries provide ways to ensure determinism. For example, Python’s built-in random module has a random.seed(123) function. For PyTorch, there is torch.use_deterministic_algorithms(True). Yes, this can result in performance degradation (why? slower, less-optimized but deterministic algorithms may be used, or, for example, some operations have no deterministic implementations on the GPU and thus fall back to CPU). But determinism was crucial to our approach, so it was definitely worth it.
In some cases (such as A100 GPUs), we also used float32 to guarantee stable outputs. For GPUs like the A6000, “auto” precision often suffices to get reproducible results.
Step 2: Deterministic Model Initialization
Our setup_model function would set up a vllm.LLM instance with carefully chosen parameters: batch size, maximum token length, tensor parallelism, and enforced data types.
We disabled PyTorch’s cudnn.benchmark to keep execution paths consistent across runs.
This overarching setup ensures that the same prompt always yields the same output on the same GPU configuration as long as the batch size does not change (more on that in a moment).
Step 3: Prompt Batching
We started by creating multiple large “prompt batches,” each sized to push a GPU to its capacity (e.g., 240 prompts). We chose this particular batch size to optimize memory usage, throughput, and guaranteed determinism on our reference GPUs.
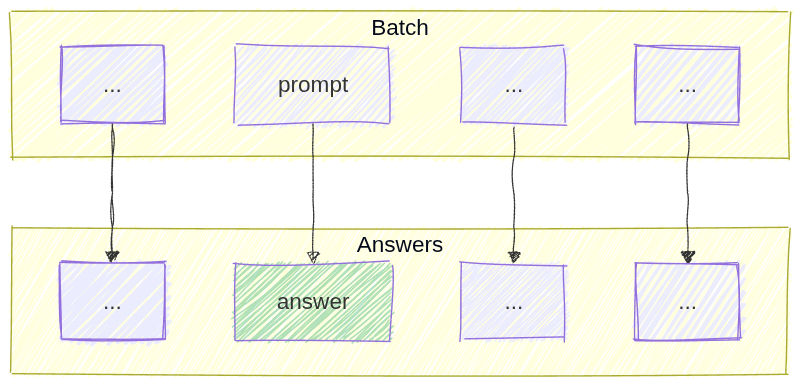
It was at this stage that we made a critical discovery: a single prompt would result in different answers if we changed the batch size…
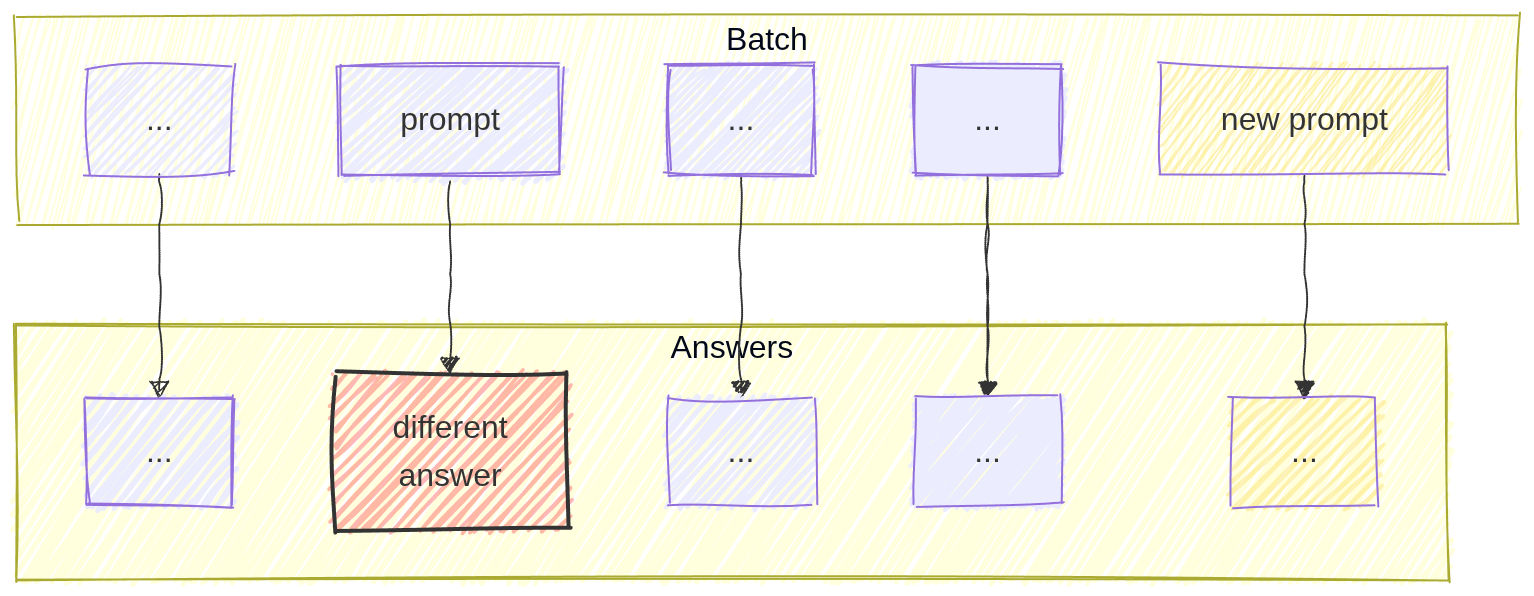
…but remained the same while the batch size was kept the same, even if mixed with different prompts!
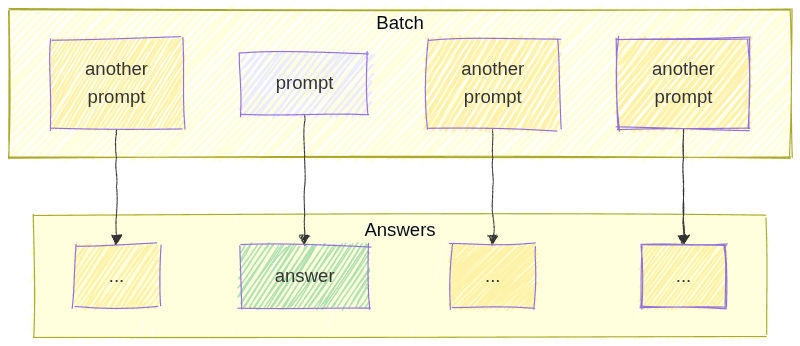
Why is that? Changing the batch size can change the internal execution path. This leads to small numerical differences or different scheduling.
This is important because we can “mix” prompts from different original batches into one test batch, as long as the new batch has the same total size.
Step 4: Mixing
So we can answer 240 prompts in one go. Any GPU can. That means we have to answer 240 x NUMBER_OF_NODES prompts to validate them? If we send only a single prompt to each node, malicious providers can pretend to have 240 nodes using a single GPU. Or maybe we can use this fact to our advantage? Can we?

Let’s find answers for a batch of 240 prompts on trusted hardware, and then… split them up and hide them among “placeholder” prompts we don’t have answers to! So one answered batch yields 240 batches of:
- 239 placeholder prompts;
- 1 answered prompt, the “real one.”
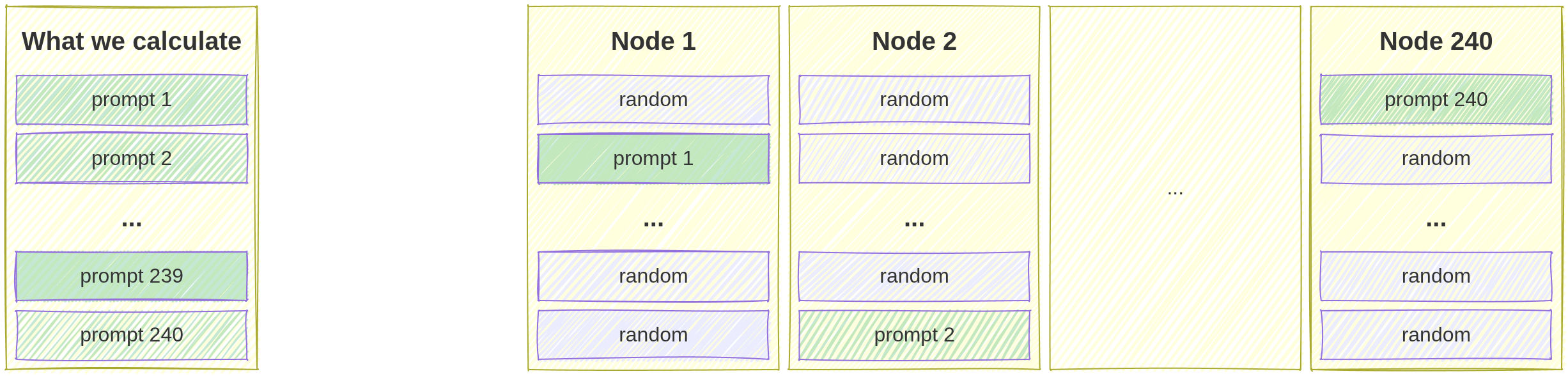
But the tested nodes will not know which of the 240 they receive is the “real one”! They have to answer all of them (in a single go, that’s GPU vectori-batchi-black-hole-magification working). And we’ll only check the one answer. Only the one. Demotivating? Well, you’re a computer, deal with it. And if the answer doesn’t match the expected one, then:
- Different hardware was used
- Different firmware was used
- A different model was used
- Model settings were tweaked
- Tricky tricks
The whole process in a nutshell
- Prepare a batch of 240 prompts
- Generate deterministic answers to all of them on trusted hardware - this is done in one go, due to GPU parallelization, etc.
- Generate 240 batches of prompts, 239 prompts in each one - we don’t generate answers to these
- Mix it up! - hide 1 “answered prompt” in each batch from step 3 - randomizing its position in the list
- Send one batch from step 4 to each provided node, have them send all responses, but only verify the one we know
- Punish nodes that failed verification
- Rinse and repeat if more than 240 nodes need to be tested concurrently.
No More Cheating… And 240x Better Efficiency!
This mixed batch approach allowed us to scale testing while minimizing compute costs. One single pass per GPU is enough to check whether it produces the correct, deterministic outputs and to measure its performance. We no longer have to re-run every original batch, which cuts our testing compute costs significantly.
Result? No more cheating!
Each prompt from the original batches must create the same output in the test batch. This means they need to match in size and seed. If there’s any difference, it could signal problems with the GPU or the provider’s processes. We can now easily verify all the hardware we supply to our users, without needing a car mechanic to come along!

What Else Can We Do With This Approach?
Could this method be successfully applied to other computational problems? Absolutely. Feel free to experiment (and let us know)!
The main idea is to hide a test case among many others. The system must compute all of them since it can't tell which will be used for verification.
This method works well when creating test cases is cheap, but computing results is costly. It doesn’t have to depend on LLMs! For example, you can use prime factorization. Generating a number is easy, but factorizing it takes a lot of computation.
If you’d like to discuss our approach further, feel free to reach out!